写在前面
最近在写毕业论文,为了更加方便的批量从知网中下载论文作为参考,便萌生出使用Python + Selenium 快速下载论文的想法。于是抽空学习了下Selenium,有了这篇文章。
环境准备
Selenium 安装
在已用的python环境中输入以下命令,安装Selenium
浏览器驱动
首先请确保当前浏览器更新到最新版本
Chrome:
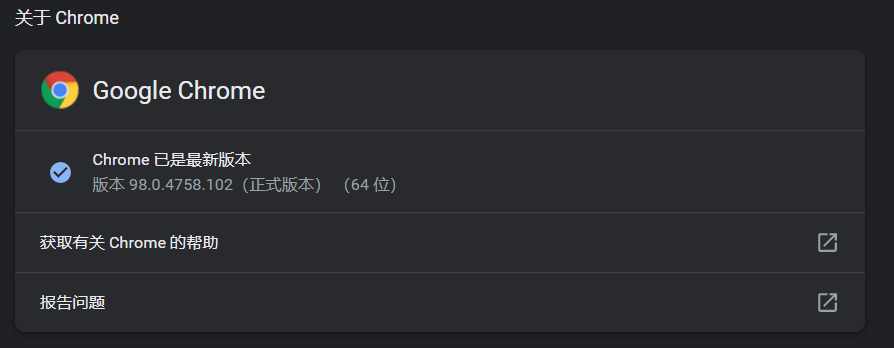 image-20220216080948580
image-20220216080948580
EDGE:
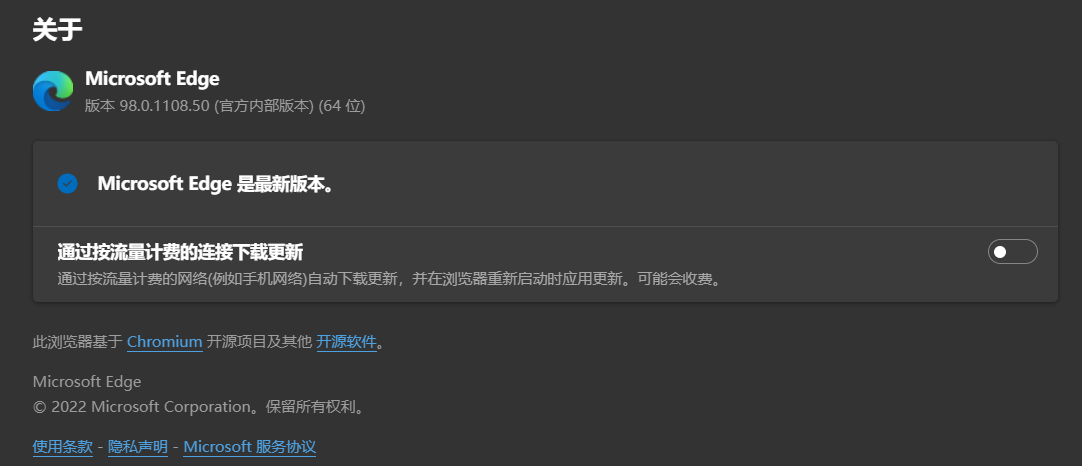 image-20220216080934081
image-20220216080934081
相应浏览器驱动的下载地址:
Chrome:ChromeDriver - WebDriver for Chrome - Downloads (chromium.org)
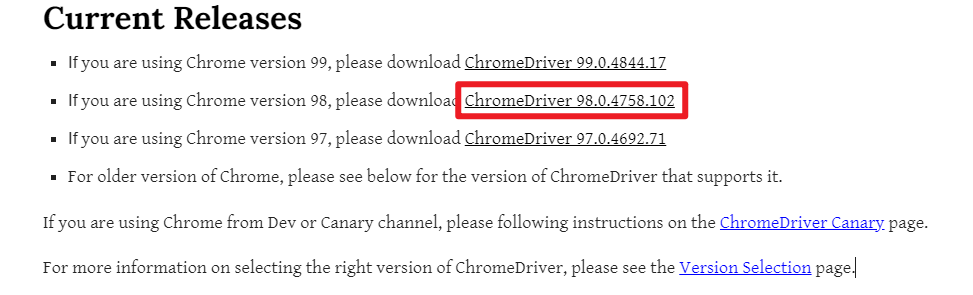 image-20220216081310947
image-20220216081310947
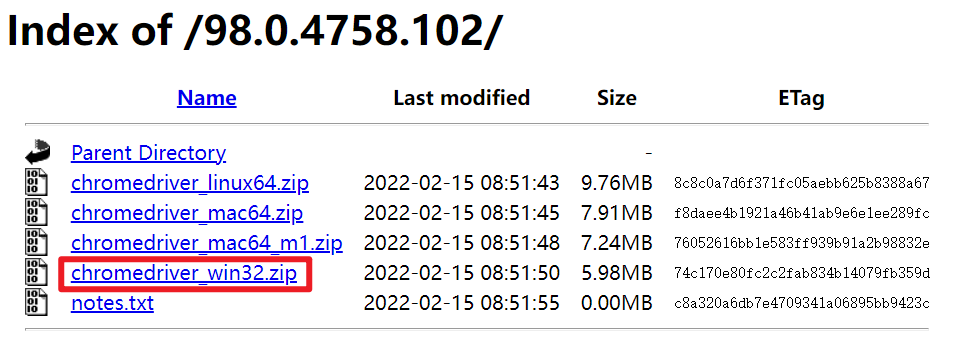 image-20220216081328290
image-20220216081328290
EDGE:Microsoft Edge Driver - Microsoft Edge Developer
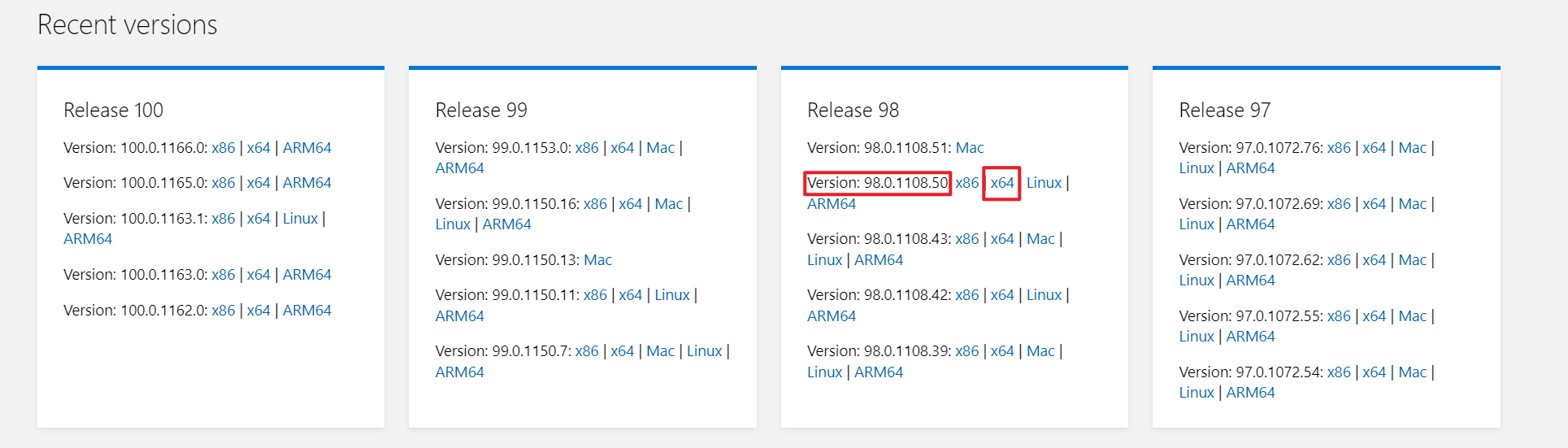 image-20220216081149351
image-20220216081149351
下载时请注意浏览器内核版本,与操作系统位数。
下载完成后的浏览器驱动可以放置在python安装目录下,也可以放置在项目的目录下。
注意:如果是Linux请放置在 /usr/bin 目录下。
开始使用
浏览器初始化
1
2
3
4
5
6
7
8
9
10
11
12
| from selenium import webdriver
options = webdriver.EdgeOptions()
options.add_argument("--headless")
options.add_argument('--disable-gpu')
browser = webdriver.Edge(options=options)
browser.implicitly_wait(3)
url = "https://www.baidu.com"
browser.get(url)
|
找到元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| from selenium.webdriver.common.by import By
elem = browser.find_element(By.NAME, "tj_login")
elem = browser.find_element(By.ID, "s-top-loginbtn")
elems = browser.find_elements(By.CLASS_NAME, "s-top-login-btn")
elem = elems[0]
css = '[class="s-top-login-btn"][name="tj_login"]'
browser.find_element(By.CSS_SELECTOR, css)
login_btn = '//*[@id="s-top-loginbtn"]'
elem = browser.find_element(By.XPATH, login_btn)
|
 image-20220216091049052
image-20220216091049052
使用F12调试模式获取XPATH,注意在动态加载的网站中,获取的XPATH可能会出现变化。
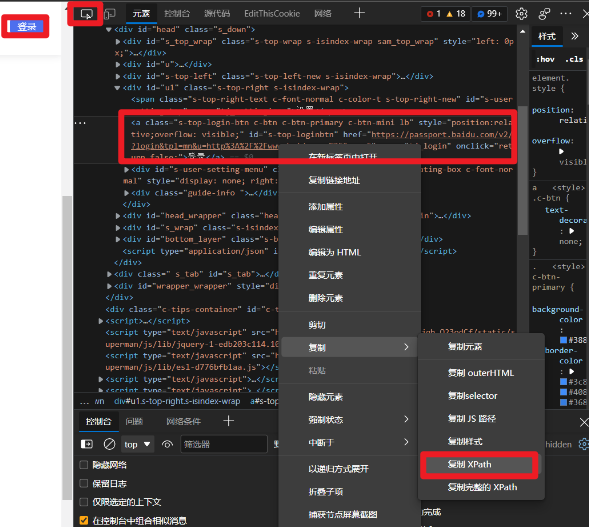 image-20220216091623418
image-20220216091623418
点击与输入
网页的操作无外乎,点击,输入与选择下拉菜单。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
elem.click()
text ="abcd"
elem.send_keys(text)
elem.select_by_index(6)
elem.select_by_visible_text('数学')
elem.select_by_value('25')
elem.clear()
|
标签栏操作
1
2
3
4
5
6
7
8
9
10
| browser.current_window_handle
browser.window_handles
browser.switch_to.window(browser.window_handles[0])
browser.switch_to.frame(iframe)
browser.switch_to.alert()
browser.close()
browser.current_url
|
Cookie保存与读取
1
2
3
4
| import json
with open('cookies.txt','w') as f:
f.write(json.dumps(browser.get_cookies()))
|
1
2
3
4
5
6
7
8
| import json
browser.delete_all_cookies()
with open('cookies.txt','r') as f:
cookies_list = json.load(f)
for cookie in cookies_list:
driver.add_cookie(cookie)
|
保存验证码
使用截图获取网页图片,确定元素位置,裁切并保存校验码。如果使用的是笔记本或高分辨率屏幕,注意系统缩放设置,本文设置的是125%缩放。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
browser.get_screenshot_as_file('screenshot.png')
element = browser.find_element(By.CLASS_NAME, 'captchaimg')
left = int(element.location['x'])
top = int(element.location['y'])
right = int(element.location['x'] + element.size['width'])
bottom = int(element.location['y'] + element.size['height'])
im = Image.open('screenshot.png')
zoom = 1.25
im = im.crop((left * zoom, top * zoom, right * zoom, bottom * zoom))
im.save('code.png')
im.show()
vcc = input("请输入验证码:")
elem = browser.find_element(By.NAME, "VerifyCode")
elem.clear()
elem.send_keys(vcc)
|
其他操作
1
2
| browser.forward()
browser.back()
|
更多资料
Python+Selenium基础入门及实践 - 简书 (jianshu.com)
Selenium之find_element_by_css_selector()的使用方法 - 简书 (jianshu.com)